6.2 Eksperimen Algoritma CLARA
Dalam eksperimen ini, kita akan menerapkan algoritma CLARA pada dataset yang terdiri dari dua variabel acak. Kita akan membangkitkan 500 sampel dari dua distribusi normal yang berbeda.
1. Memuat library yang diperlukan
Library pertama adalah cluster, yang digunakan untuk melakukan analisis clustering dengan berbagai algoritma, seperti PAM (Partitioning Around Medoids) dan CLARA (Clustering Large Applications). Dalam kasus ini, CLARA digunakan untuk mengelompokkan data besar secara efisien. Library kedua adalah ggplot2, yang digunakan untuk membuat visualisasi data secara estetis dan informatif. Dengan pendekatan layered grammar of graphics, ggplot2 memungkinkan pembuatan grafik kompleks, seperti visualisasi hasil clustering berdasarkan dua variabel dalam dataset.
2. Membangkitkan data acak
Data acak dibangkitkan menggunakan fungsi rnorm() dalam bahasa pemrograman R. Fungsi rnorm() digunakan untuk menghasilkan angka acak yang terdistribusi normal, dengan parameter pertama menunjukkan jumlah data yang ingin dibangkitkan, parameter kedua adalah rata-rata (mean), dan parameter ketiga adalah simpangan baku (standard deviation). Pada bagian pertama, dua set data acak dengan jumlah 200 titik data untuk setiap variabel x dan y dihasilkan, yang masing-masing memiliki distribusi normal dengan rata-rata 0 dan simpangan baku 8. Data ini kemudian digabungkan menggunakan fungsi rbind(). Pada bagian kedua, dua set data tambahan dengan jumlah 300 titik data masing-masing untuk variabel x dan y dihasilkan, dengan rata-rata 50 dan simpangan baku 8. Akhirnya, nama kolom untuk data acak tersebut ditentukan dengan fungsi colnames(), yaitu x untuk variabel pertama dan y untuk variabel kedua. Hasilnya adalah sebuah matriks data dua kolom yang berisi dua grup data acak dengan distribusi normal berbeda.
3. Visualisasi data acak
Visualisasi data acak di atas dilakukan menggunakan paket ggplot2 di R. Fungsi ggplot() digunakan untuk memulai pembuatan plot, dengan parameter data berisi data yang ingin divisualisasikan, dan aes() untuk menentukan hubungan antara variabel-variabel yang akan diplot, yaitu x dan y. Selanjutnya, fungsi geom_point() digunakan untuk membuat grafik titik (scatter plot), dengan argumen alpha = 0.5 untuk memberikan tingkat transparansi pada titik-titik, sehingga memungkinkan visualisasi yang lebih jelas ketika titik-titik saling tumpang tindih. Judul plot diatur menggunakan labs() dengan parameter title, x, dan y untuk memberikan label pada plot dan sumbu X serta Y. Terakhir, theme_minimal() diterapkan untuk memberikan tampilan plot yang bersih dan sederhana. Hasil dari kode ini adalah visualisasi data acak dalam bentuk scatter plot dengan dua variabel, menunjukkan dua kelompok data dengan distribusi normal yang berbeda.
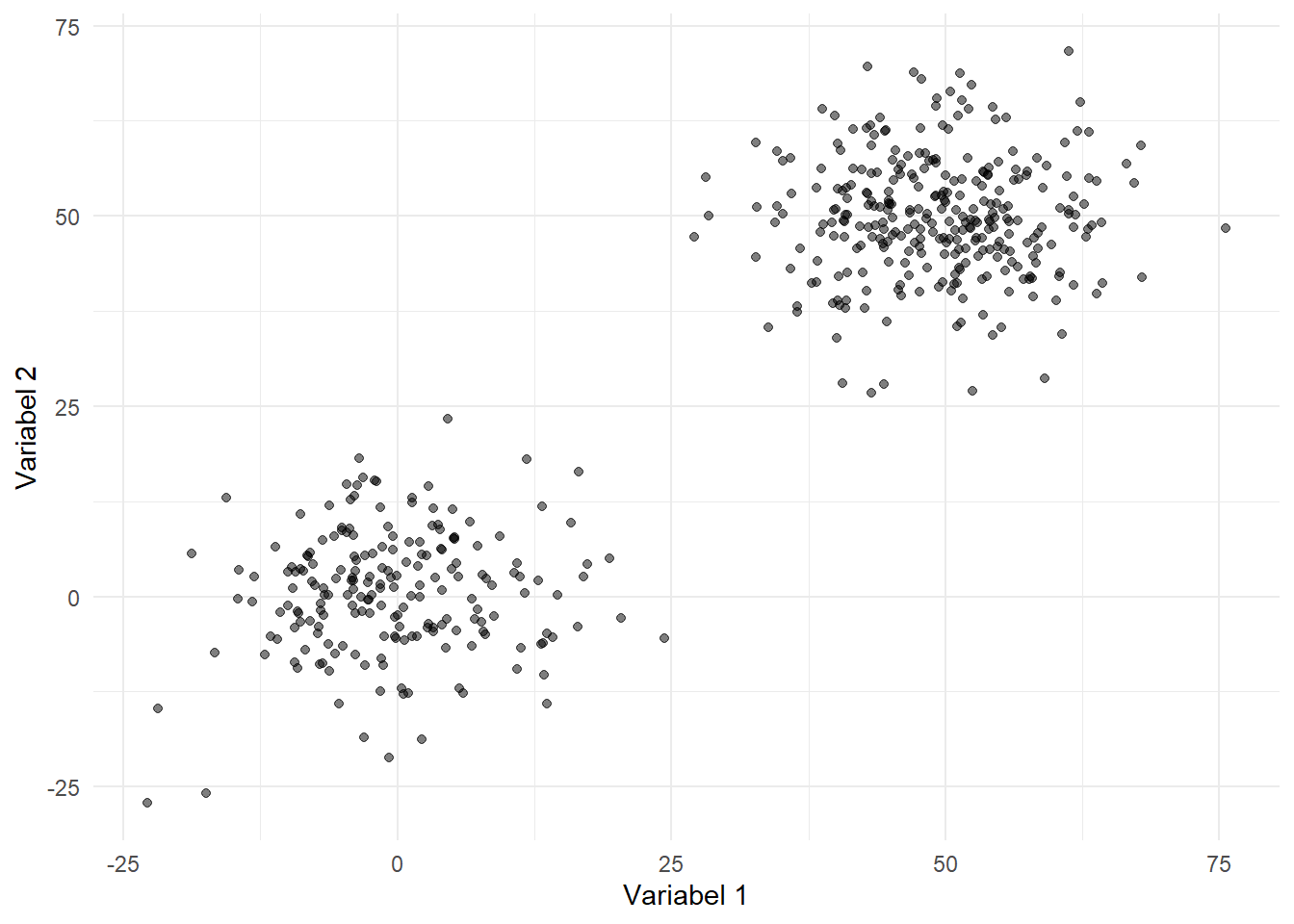
Gambar 6.1: Visualisasi Data
4. Mencari Jumlah Cluster Optimal
Visualisasi jumlah klaster yang optimal dilakukan menggunakan metode silhouette dengan paket cluster dan factoextra di R. Fungsi fviz_nbclust() digunakan untuk menilai jumlah klaster terbaik berdasarkan metode yang dipilih, dalam hal ini menggunakan algoritma clara (Clustering Large Applications). Metode silhouette mengukur seberapa baik setiap objek dipisahkan dari klaster lain, dengan nilai yang lebih tinggi menunjukkan pemisahan yang lebih baik. Parameter method = "silhouette" mengindikasikan bahwa visualisasi menggunakan metode tersebut. Hasilnya akan memperlihatkan grafik yang menggambarkan nilai rata-rata silhouette untuk berbagai jumlah klaster. Terakhir, fungsi theme_classic() diterapkan untuk memberikan tampilan plot yang bersih dan sederhana. Grafik ini dapat membantu dalam menentukan jumlah klaster yang paling sesuai dengan data berdasarkan evaluasi kualitas pemisahan antar klaster.
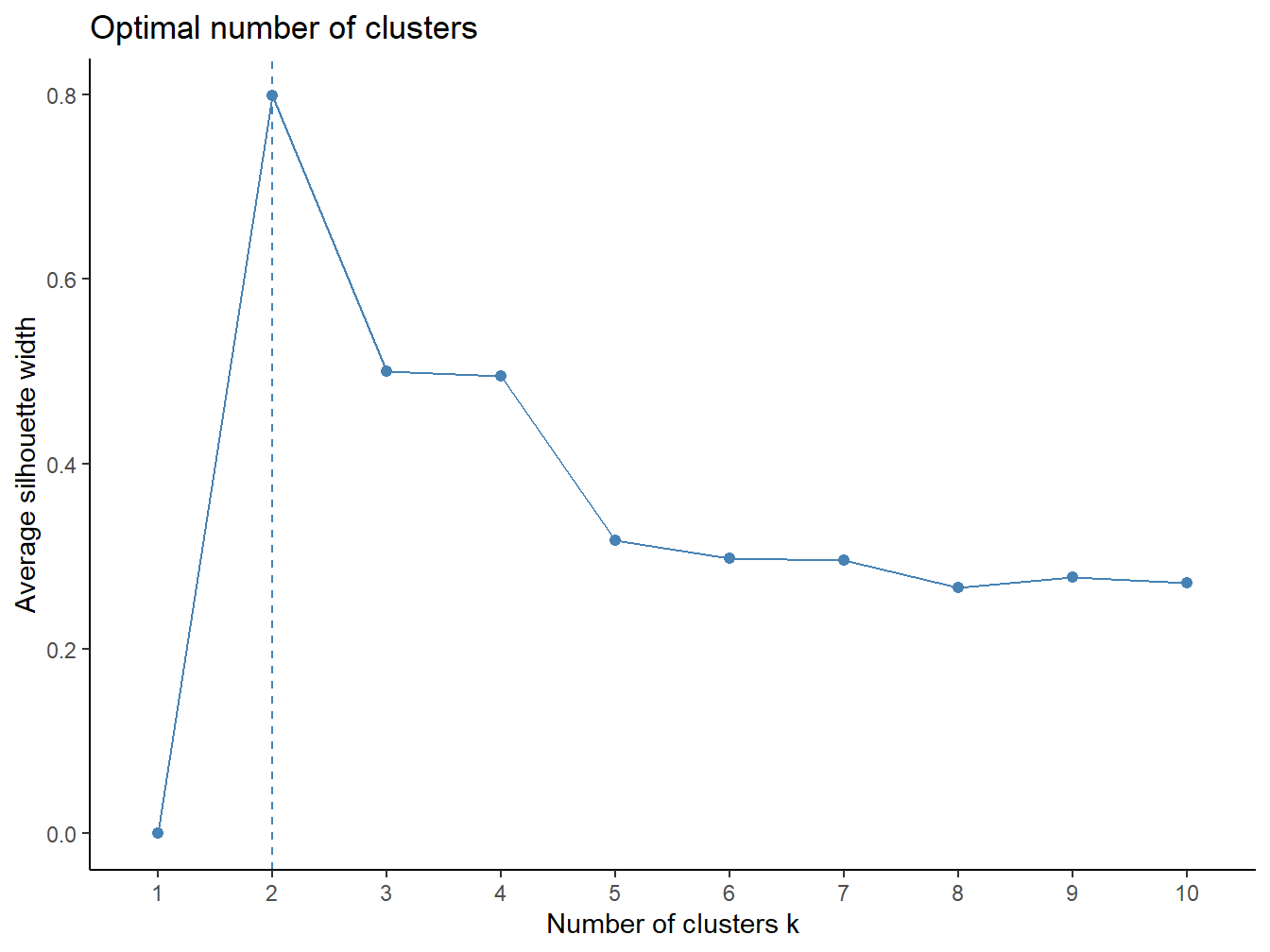
Gambar 6.2: Jumlah Cluster Optimal
5. Menjalankan CLARA
Algoritma CLARA (Clustering Large Applications) digunakan untuk melakukan klasterisasi data dengan jumlah klaster yang ditentukan sebanyak 2, yang ditetapkan melalui parameter k = 2. Fungsi clara() dari paket cluster di R dirancang untuk melakukan klasterisasi pada dataset besar dengan cara mengacak sampel data untuk mempercepat proses klasterisasi. Parameter samples = 5 menunjukkan bahwa lima sampel data acak akan diambil untuk setiap iterasi klasterisasi. Hasil dari klasterisasi ini disimpan dalam objek clara_result, yang berisi informasi tentang klaster yang terbentuk, termasuk elemen-elemen data yang termasuk dalam setiap klaster dan pusat klaster.
6. Evaluasi hasil
print(clara_result) digunakan untuk menampilkan hasil dari proses klasterisasi yang dilakukan dengan algoritma CLARA. Setelah data dikelompokkan menjadi dua klaster menggunakan parameter k = 2, hasil ini memberikan informasi tentang bagaimana data dibagi. Secara spesifik, hasil tersebut akan menunjukkan anggota klaster, yaitu data mana yang tergabung dalam setiap klaster, serta pusat klaster, yang menggambarkan titik tengah dari masing-masing klaster. Selain itu, hasil ini juga dapat mencakup ukuran atau indeks kualitas klaster, yang digunakan untuk mengevaluasi sejauh mana klaster-klaster tersebut terpisah dengan baik satu sama lain. Dengan demikian, fungsi print(clara_result) memberikan gambaran yang jelas tentang hasil klasterisasi dan seberapa baik data dapat dikelompokkan dalam dua klaster.
print(clara_result)
#> Call: clara(x = data, k = 2, samples = 5)
#> Medoids:
#> x y
#> [1,] -0.5495492 2.458514
#> [2,] 47.5964047 50.892735
#> Objective function: 9.9971
#> Clustering vector: int [1:500] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ...
#> Cluster sizes: 200 300
#> Best sample:
#> [1] 6 45 51 67 75 85 90 94 97 110 111 160 168 170 176 181 201 219 249
#> [20] 260 264 275 296 304 317 319 337 361 362 369 370 374 379 397 398 411 420 422
#> [39] 424 436 448 458 465 489
#>
#> Available components:
#> [1] "sample" "medoids" "i.med" "clustering" "objective"
#> [6] "clusinfo" "diss" "call" "silinfo" "data"7. Visualisasi Hasil Cluster
Visualisasi silhouette digunakan untuk mengevaluasi kualitas klaster yang dihasilkan oleh algoritma CLARA. Fungsi silhouette() menghitung nilai silhouette untuk setiap titik data berdasarkan klaster yang telah ditetapkan (clara_result$clustering) dan jarak antar data (dist(data)). Nilai silhouette mengukur sejauh mana setiap titik data berada dalam klaster yang benar, dengan nilai mendekati +1 menunjukkan bahwa titik data tersebut sangat cocok dengan klasternya, sedangkan nilai mendekati -1 menunjukkan bahwa titik tersebut lebih cocok dengan klaster lain.
Selanjutnya, fungsi plot(sil, border = NA) digunakan untuk menghasilkan plot visualisasi dari hasil silhouette. Parameter border = NA menghilangkan batas pada setiap segmen plot untuk memberikan tampilan yang lebih bersih. Hasil visualisasi ini memberikan gambaran tentang kualitas pemisahan antar klaster, dengan tinggi nilai silhouette menunjukkan klasterisasi yang baik.
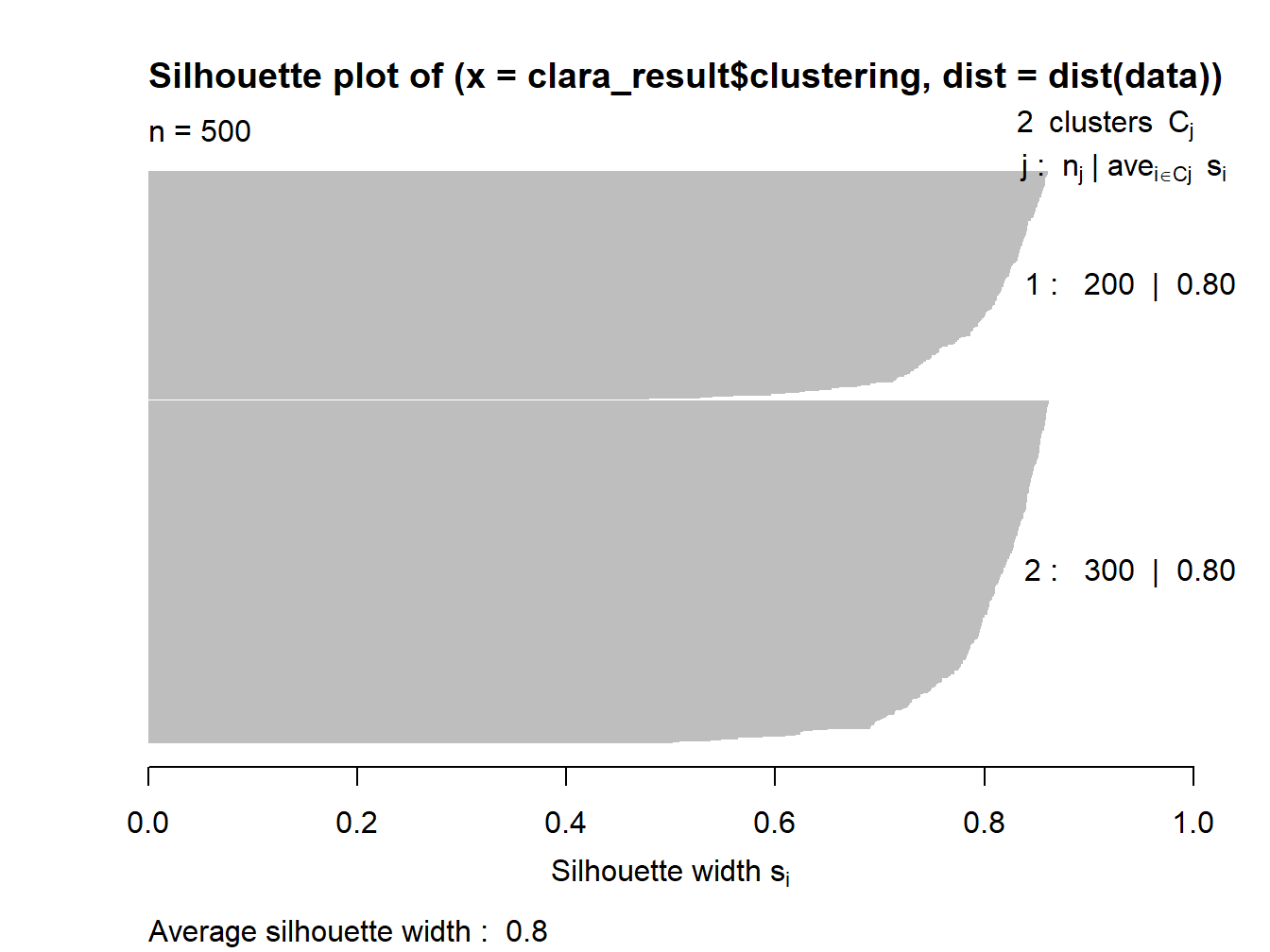
Gambar 6.3: Visualisasi silhouette
Kode ini menggunakan fungsi fviz_cluster() untuk memvisualisasikan hasil klasterisasi yang dilakukan dengan algoritma CLARA. Visualisasi ini menampilkan titik-titik data yang dikelompokkan berdasarkan klaster yang telah ditentukan, dengan dua klaster yang masing-masing diberi warna berbeda menggunakan palet warna #00AFBB dan #FC4E07. Elips konsentrasi (ellipse.type = "t") ditambahkan di sekitar setiap klaster, yang menunjukkan area distribusi data dalam klaster tersebut, memberikan gambaran tentang seberapa padat atau tersebarnya data. Dengan parameter geom = "point", visualisasi ini menampilkan titik-titik data, dan ukuran titik diatur menggunakan pointsize = 1. Tema klasik (theme_classic()) diterapkan untuk memberikan tampilan plot yang bersih dan sederhana. Hasil dari kode ini adalah visualisasi yang jelas tentang pembagian data ke dalam dua klaster dengan warna yang berbeda, serta gambaran tentang penyebaran data di dalam setiap klaster.
fviz_cluster(clara_result,
palette = c("#00AFBB", "#FC4E07"), # color palette
ellipse.type = "t", # Concentration ellipse
geom = "point", pointsize = 1,
ggtheme = theme_classic()
)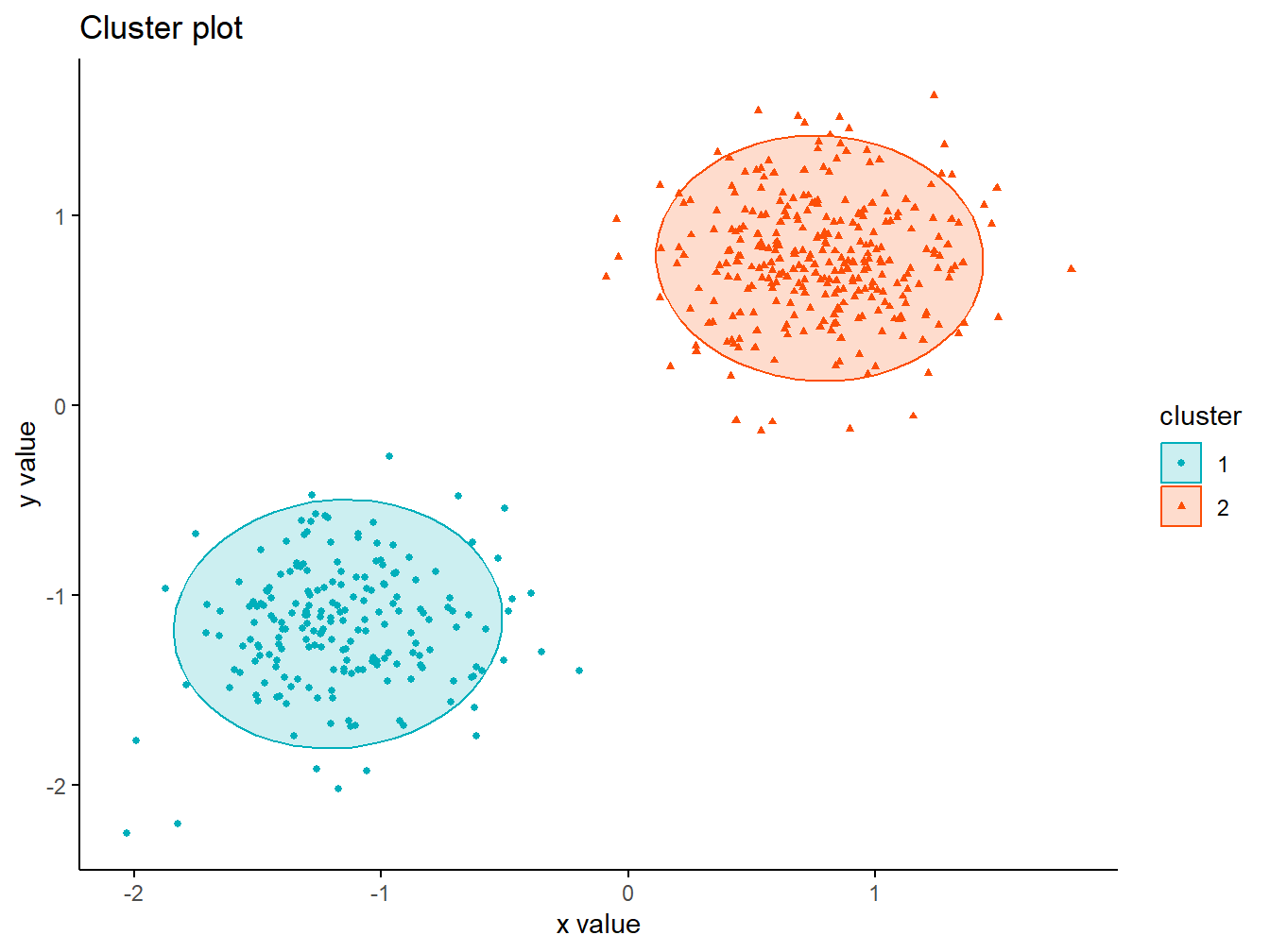
Gambar 6.4: Visualisasi Hasil Cluster